


Recursion in Apex has a bit of a reputation. Many Salesforce developers first hear the term when a trigger unexpectedly calls itself over and over, leading to the dreaded “Maximum trigger depth exceeded” error. It’s easy to assume recursion = bad, especially if you don’t come from a computer science background. In reality, recursion is a fundamental programming concept, a powerful tool when used intentionally, but a source of tricky bugs when it happens unintentionally. This post will simplify recursion in the context of Apex, exploring both the pitfalls of unintended recursive triggers and the value of deliberate recursion for solving certain problems. We’ll look at code examples of each, discuss how recursion interacts with Salesforce governor limits and performance, and cover best practices (like static flags and trigger patterns) to prevent unwanted loops. By the end, you’ll know when to fear recursion, when to embrace it, and how to keep your triggers from going rogue.
What is Recursion in Apex?
At its core, recursion is when a function (method) calls itself. A recursive method typically solves a problem by breaking it down into smaller sub-problems, calling itself for each sub-part, and using a termination condition to stop. Whenever a method is called, it’s placed on the call stack. In Apex, there is a limit to how deep this stack can grow, an Apex method cannot call itself more than 1000 times before hitting a limit. This stack depth limit is a safety net to prevent infinite loops in a single transaction. If you exceed it, you’ll get a runtime error (for example, “Maximum stack depth reached: 1001”).
It’s important to distinguish function recursion from trigger recursion. In Apex triggers, recursion refers to a trigger firing repeatedly on the same records or in a loop. Salesforce enforces a separate limit for trigger invocations: a chain of triggers that keep firing cannot exceed 16 iterations. In other words, if performing DML in a trigger causes another trigger (or the same trigger) to run, which causes another DML and so on, the platform will halt after 16 nested trigger calls to prevent an infinite loop. This usually surfaces as the “Maximum trigger depth exceeded” error. These limits (1000 for call stack depth, 16 for trigger recursion depth) are there to protect the multi-tenant environment.
So, recursion itself isn’t “bad”, it’s a natural concept, but in Apex you must use it carefully due to these limits and the governor rules. Next, we’ll explore two very different scenarios: one where recursion sneaks up as a bug in triggers, and another where recursion is intentionally used to solve a problem like traversing a tree.
Unintentional Recursion in Triggers (When Triggers Go Rogue)
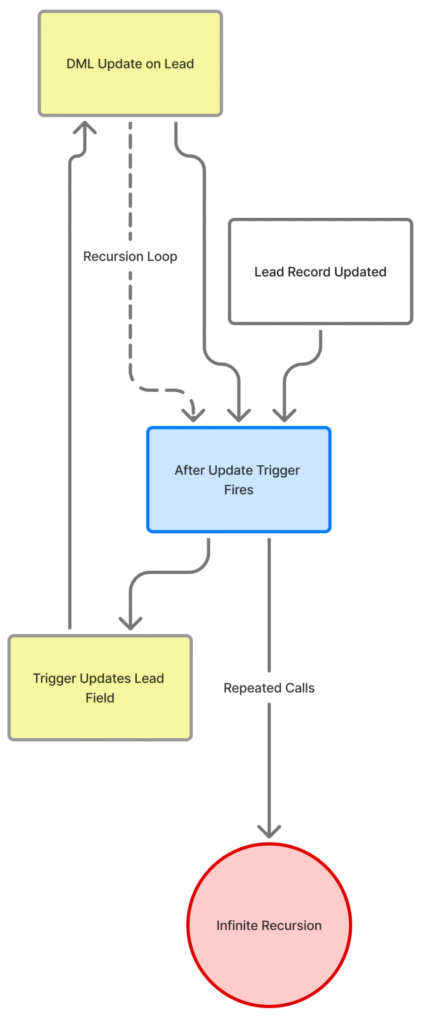
Unintentional recursion in Salesforce often involves triggers calling themselves (directly or indirectly) in an endless loop. This typically happens when a trigger performs a DML update that causes the same trigger (or another trigger on the same object) to execute again, over and over. Such recursive trigger loops can be direct (trigger updates its own records) or indirect (Trigger on Object A updates Object B, which has a trigger that updates Object A back). Eventually, Salesforce will notice the runaway loop and throw an error to stop it, e.g. “maximum trigger depth exceeded”.
Example – A Recursive Trigger Bug: Consider a naive trigger on Lead that tries to set a custom Date field to the Lead’s LastModifiedDate in an after update context. The intent might be to copy the last modified timestamp to a Date-only field. But doing this in an after-trigger means we update the Lead within its own trigger context, causing the trigger to fire again and again.
// *** Dangerous recursive trigger example ***
trigger LeadSetDateTrigger on Lead (after insert, after update) {
List<Lead> leadsToUpdate = new List<Lead>();
for (Lead record : Trigger.new) {
// Set custom date field to the date part of LastModifiedDate
record.Last_Modified_Date__c = record.LastModifiedDate.date();
leadsToUpdate.add(record);
}
if (!leadsToUpdate.isEmpty()) {
update leadsToUpdate; // This update will re-fire this trigger on the same leads
}
}In this example, inserting or updating a Lead will cause the trigger to run, which issues an update on those same Lead records, causing the trigger to run again, and so on. This self-invocation loop will continue until Salesforce’s trigger depth limit (16) is hit, at which point the transaction will fail. This is a classic unintentional recursion in a trigger.
Unintentional trigger recursion can also happen across multiple objects or automation tools. For instance, object A’s trigger updates object B, and object B’s trigger updates object A, you’ve effectively created a circular update loop. The path can even involve workflows, Process Builders, or Flow triggers in between, making it hard to diagnose. The key sign is that a seemingly simple update results in repeated trigger execution and eventually a runtime limit error.
Impact: Aside from hitting the 16 trigger invocation limit, recursive triggers waste a lot of resources. They can perform redundant DML operations, consume CPU time, and risk hitting other governor limits (SOQL or DML limits) because the same code runs multiple times. It’s a scenario where the platform is doing far more work than intended, often leading to performance issues or governor limit exceptions. Clearly, we want to avoid these accidental loops.
How do we prevent triggers from going rogue? We’ll dive into best practices in a later section, but the short answer is: use safeguards in your trigger code. Common approaches include tracking whether a trigger has already run for a given record (using static flags or sets) and structuring trigger logic to only execute when necessary (for example, only if certain fields changed, using Trigger.oldMap comparisons). Before that, let’s look at how recursion isn’t always evil, there are times you actually want a function to call itself.
Intentional Recursion: Controlled Use Cases (Tree Traversal & More)
Recursion is a useful technique when a problem can naturally be broken into similar sub-problems. In Apex (despite the 1000-call limitation), you can leverage recursion for certain algorithms or data processing tasks. A classic example is traversing a hierarchical data structure, such as an organizational chart, a bill of materials, or an Account hierarchy with parent-child relationships.
Imagine you have an Account and you want to retrieve all its descendant accounts (children, grandchildren, etc.) or perhaps calculate a cumulative value from all those related records. You could do this with loops and multiple SOQL queries, but a recursive approach can be more elegant. Each account’s children can be processed in the same way as the top account, making it a perfect scenario for recursion.
Example – Recursively Traversing an Account Hierarchy: Below is a simplified example of a recursive Apex method that prints an Account hierarchy. It starts at a top Account record, then recursively visits all child accounts, then their children, and so on. (In practice, you would want to bulkify the queries or pre-fetch data to avoid hitting SOQL limits, but this example illustrates the recursive structure):
public class AccountHierarchyUtil {
public static void traverseAndPrint(Account parentAcct) {
System.debug('Visiting Account: ' + parentAcct.Name);
// Query direct children of this account
List<Account> childAccounts = [SELECT Id, Name FROM Account
WHERE ParentId = :parentAcct.Id];
for (Account child : childAccounts) {
// Recursively call the same method for each child
traverseAndPrint(child);
}
// When there are no more children, the recursion unwinds.
}
}If A1 is a top-level account that has two child accounts (A2 and A3), and A2 in turn has children A4 and A5, calling traverseAndPrint(A1) will debug-log the accounts in hierarchical order. The method calls itself for each child account, diving deeper until it reaches accounts with no children (base case), at which point those calls return and the stack unwinds.
This approach is intuitive: the code to handle an account’s children is the same regardless of depth, so recursion avoids having to write nested loops for each level. A real-world example of this can be seen in a Visualforce page that displays an account hierarchy tree, a helper function was written to recursively add child accounts to a list in the proper order
Other uses of deliberate recursion: Besides tree traversal, you might use recursion for algorithms like computing factorials, navigating complex JSON/XML structures, or performing divide-and-conquer logic. For instance, a recursive Apex method can compute a factorial n! by calling itself with n-1 (with a base case at 1 or 0), although Apex’s lack of tail-call optimization and the stack limit means you wouldn’t do this for very large n. As another example, if you implement a custom graph traversal or need to explore relationships that aren’t easily handled with SOQL alone, a recursive approach can simplify the code.
Be mindful of limits: Apex is not as recursion-friendly as some languages. Apart from the 1000-depth guard, each recursive call consumes some CPU time and some stack memory. In fact, recursive methods in Apex tend to be less efficient than iterative solutions. One experiment showed a recursive factorial took ~148 ms, whereas an equivalent iterative solution took ~30 ms for the same input. The difference is due to function call overhead and Apex’s runtime costs. So, while recursion can make code cleaner and easier to read, always consider the performance implications and ensure the recursion will terminate in a reasonable number of steps.
Impact of Recursion on Governor Limits and Performance
Recursion in Apex needs to play within the confines of Salesforce’s governor limits and execution rules:
- Maximum Trigger Depth: As noted, Salesforce allows at most 16 nested trigger invocations in one transaction. An unhandled recursive trigger will hit this limit and throw an error. Even before hitting 16, you might have done a lot of unnecessary work in those repeated executions. This is why preventing trigger recursion is critical – you usually never want a trigger to fire 16 times in a chain!
- Stack Depth Limit (1000): For non-trigger recursion (e.g., a utility method calling itself), the hard limit is 1000 calls deep. If you accidentally write a method that keeps calling itself without a base case (or with one that isn’t reached due to a bug), you’ll hit a “stack depth exceeded” error around 1000. This is essentially an infinite loop protection. Hitting this likely means your code has a logic flaw causing runaway recursion.
- CPU Time and Heap: Every recursive call adds some overhead. Deep or heavy recursion can consume a lot of CPU time, which is capped per transaction (generally 10 seconds synchronous, 60 seconds async). If your recursion does a lot of processing at each step or goes very deep, you risk hitting CPU timeout. Likewise, building up large recursive data structures can eat into the heap size limit. Always assess the complexity: e.g. O(n) or O(n^2) calls can be fine for small n, but problematic if n grows large.
- SOQL/DML Limits: A poorly implemented recursion might perform a SOQL query or DML operation on each call. Since we have limits like 100 SOQL queries and 150 DML statements per transaction, an unchecked recursive loop could easily burn through those if, say, each recursion level does a query. In our
traverseAndPrintexample above, if an account hierarchy had 101 levels, that simplistic approach would run 101 SOQL queries – breaching the limit. The takeaway is to avoid putting DML or SOQL inside a deep recursion unless you’re sure the depth is limited or you’ve bulkified the approach. Often, a better pattern is to gather data in one go (or a few chunks) and then use recursion on in-memory lists or maps of that data. - Performance vs. Readability: As mentioned, recursion can be slower than iterative logic in Apex. Each function call has overhead, and Apex isn’t optimized for tail recursion elimination. For example, computing Fibonacci numbers recursively would be dramatically slower (and hit limits for moderately large inputs) compared to an iterative loop. Use recursion for clarity and logical simplicity, but not when maximum performance is required for large data volumes. Always test and ensure your recursive approach doesn’t risk governor limits on realistic data sizes.
In summary, think of recursion in Apex as a sharp tool – very useful for certain jobs, but you must handle it with care. Now, let’s focus on strategies to prevent the unwanted kind of recursion (trigger loops) which is a common challenge for Salesforce developers.
Best Practices to Prevent Unwanted Recursion in Triggers
Handling recursion is such a common concern in trigger development that a number of best practices and patterns have emerged in the Salesforce community. Here are some proven techniques to control and prevent unwanted trigger recursion:
Use Static Variables as Flags
A classic approach is to use a static Boolean flag in an Apex class (often called a “recursion guard”). Static variables persist for the duration of the transaction, including across trigger contexts. You set a flag when your trigger runs the first time, and then any subsequent entry of the trigger will see the flag and immediately exit, avoiding re-execution. For example:
// Recursion guard class
public class TriggerRunOnce {
public static Boolean isRunning = false;
}
trigger AccountTrigger on Account (after update) {
if (TriggerRunOnce.isRunning) {
return; // Trigger already ran in this transaction, prevent re-entry
}
TriggerRunOnce.isRunning = true;
// ... perform actions (e.g., do some DML that would normally re-invoke trigger) ...
// Example: update parent account based on child changes
List<Account> parentAccounts = new List<Account>();
for (Account child : Trigger.new) {
if (child.ParentId != null) {
parentAccounts.add(new Account(Id = child.ParentId, Last_Child_Update__c = System.now()));
}
}
if (!parentAccounts.isEmpty()) {
update parentAccounts;
}
TriggerRunOnce.isRunning = false; // Reset flag for next chunk
}In this snippet, the static flag TriggerRunOnce.isRunning ensures the update to parent accounts doesn’t cause the trigger to run again on those parent records in an infinite loop. We set the flag to true right before performing the internal update, and then set it back to false immediately after. This way, if the trigger is invoked again for a different batch of records in the same transaction, it will still execute (the flag was reset), avoiding the pitfall of skipping legitimate second batches. Important: A simple static Boolean that isn’t reset can become an anti-pattern. If you set a static flag once and never unset it, then in a bulk operation (say 500 records causing trigger to execute twice, 200 per chunk), the second execution will find the flag still true and skip entirely, leaving some records unprocessed. This is why we toggle the flag only around the specific DML that needs guarding, or use a more sophisticated tracking as below.
Use Static Sets or Maps to Track Processed Records:
A more granular approach is to keep a static Set<Id> of record IDs that have been processed by your trigger logic. Each time the trigger runs, check if the record’s Id is in the set; if so, skip it, otherwise handle it and add its Id to the set. This prevents the same record from being processed multiple times in one transaction. Unlike a blunt boolean flag, a set of IDs can handle large batches and partial successes. For example, if a workflow field update causes a second update trigger, your code can see “oh, I already handled this record’s changes” and not do it again. Apex developers often prefer a static Set/Map because it’s more flexible, especially in mixed DML scenarios. One implementation is:
public class TriggerRecursionGuard {
public static Set<Id> processedIds = new Set<Id>();
}
trigger ContactTrigger on Contact (after update) {
for (Contact con : Trigger.new) {
if (!TriggerRecursionGuard.processedIds.contains(con.Id)) {
TriggerRecursionGuard.processedIds.add(con.Id);
// ... perform trigger logic for this contact ...
}
}
}This ensures each Contact is only acted on once. However, note that if your transaction involves different operations (insert then update in the same transaction, or different triggers in the call stack), a single set might not distinguish contexts. You might accidentally prevent legitimate processing of an insert followed by an update on the same record. To refine this, some devs use a static Map keyed by trigger context or a compound key of (recordId + operation). For example, a map from (ObjectName + triggerEvent) to a set of Ids, so you track “Contact-afterUpdate” separately from “Contact-afterInsert”. This is an advanced optimization to avoid false positives in recursion detection.
One caution with static collections: remember to clear them if needed, or design them to only grow with unique IDs. In long transactions with many records, a static set of IDs could grow large, but typically these patterns are only used to track IDs within one trigger’s context, so they won’t blow up memory. Also be aware that if you perform a partial DML (allOrNone = false) and some records fail, static flags/sets may not behave as expected in the error context (since the transaction might not fully roll back static variable state). But for most scenarios, static collections are reliable within a single transaction
Recursion in Apex and Use Trigger.oldMap (for Update triggers)
Often, not every trigger invocation is actually a recursion scenario. Sometimes a trigger runs multiple times legitimately (e.g., record gets updated twice in a transaction), but you only want your logic to execute if a specific field changed or a condition is met. By comparing the old and new values of a record, you can ensure your code runs only when needed and doesn’t create a loop. For example, in an Opportunity trigger, you might do:
for (Opportunity opp : Trigger.new) {
Opportunity oldOpp = Trigger.oldMap.get(opp.Id);
if (opp.StageName != oldOpp.StageName) {
// Stage changed- perform some action (e.g., create a Task)
// If StageName didn't actually change, skip to avoid unnecessary DML
}
}Here, if your trigger itself updates the StageName, it would cause a second trigger execution, but in the second run Trigger.oldMap will still show the old stage (because Salesforce doesn’t refresh oldMap for the second update), referenced from StackOverflow. Comparing new vs. old in a naive way could incorrectly think “Stage changed” again and repeat the logic, causing recursion. So while using oldMap is a best practice to avoid redundant operations, be mindful that platform nuances (like workflow field updates not updating Trigger.old) can make a simple comparison insufficient in some cases. This is where static flags might still be needed in combination. In summary, oldMap comparisons help prevent unnecessary trigger logic, which indirectly helps avoid recursion by not performing secondary DML unless required.
One Trigger per Object & Logic-less Triggers
A recommended design pattern is to have a single trigger per sObject and delegate logic to a handler class. This doesn’t directly stop recursion, but it makes it easier to manage control flags and ensure consistent behavior. With all logic funneled through one point, you can implement a check at the top (like the static flag or set approach) that covers all scenarios. Salesforce architects also advise keeping triggers logic-free, just call out to a class that does the work. This makes maintenance easier and consolidates where you handle things like recursion control.
Many trigger frameworks (popular ones include Trigger Handler frameworks or fflib) provide built-in ways to prevent multiple executions. For example, a framework might automatically short-circuit subsequent trigger calls on the same records, or allow you to disable triggers programmatically during a specific operation. Using a trigger framework or pattern is a hallmark of professional Apex development. It also ties into general best practices: having one trigger per object, ensuring 100% test coverage, and carefully controlling trigger execution order (since Salesforce doesn’t guarantee order if you have multiple triggers on the same object)
Recursion Prevention Handler Classes
This concept is essentially what we demonstrated with static flags, but some teams implement a dedicated “Recursion Prevention” utility class. Such a class might offer methods like isFirstRun(Object record) or manage a map of processed records under the hood. The idea is to encapsulate the logic of tracking recursion so your triggers call a clean API, e.g., if(RecursionPreventer.shouldProcess(triggerContextId)) { ... }. Whether simple or abstracted, the goal is the same: detect that a trigger has fired before on the same record(s) and skip or handle accordingly. As an example from the community, one could create a generic handler where you register a record Id when you start processing it and remove it when done, thereby preventing re-entry if it’s already in progress.
In practice, you often combine several of these techniques. For instance, a trigger might use an oldMap check to only do work on real field changes, and also a static set to prevent double-processing those records if a workflow triggers an update. And all of that could be within a single trigger per object, using a trigger handler class that implements the static tracking.
The bottom line: Defensive coding in triggers is crucial. Assume that any DML you do could re-invoke triggers (on the same object or others) and guard against it. By using static flags/sets correctly and following trigger best practices, you can avoid infinite loops and ensure your trigger logic runs only when intended. Salesforce even documents the static boolean flag technique as a way to prevent recursive triggers – though as we saw, a naive implementation of it can be problematic for bulk scenarios. The modern consensus is to prefer sets or more robust frameworks for recursion control
Conclusion & Key Takeaways
Recursion in Apex is a double-edged sword. Unchecked, it can wreak havoc with trigger logic and governor limits; used wisely, it can simplify code for certain tasks. As an Apex developer (whether you’re a beginner or an experienced architect), it’s important to recognize both sides and apply best practices. Here are the key takeaways from our discussion:
- Recursion in apex Basics: A recursive method is one that calls itself. Apex limits recursive call depth to 1000 to prevent infinite loops. Always ensure a recursion has a clear base case to terminate, otherwise you’ll hit governor limits or runtime errors.
- Trigger Recursion is Dangerous: Unintentional trigger recursion (like a trigger updating a record and causing itself to fire again) can quickly lead to “Maximum trigger depth exceeded” errors after 16 iterations. It also wastes CPU time and can blow past SOQL/DML limits. Always be aware when writing triggers that any DML can fire additional triggers, plan for it.
- Use Guards to Prevent Loops: Implement safeguards in triggers to prevent recursive re-entry. Static flags or collections are your friends, use a static Boolean or Set/Map in a helper class to track if your trigger has already processed certain records in the current transaction. This will stop infinite loops and also avoid double-processing records when the same trigger runs multiple times.
- Prefer Sets over Simple Flags: A single static boolean flag (e.g.,
isFirstRun) might work in very limited cases but is generally an anti-pattern for bulk scenarios. It will cause later batches of records to be skipped. Instead, use aSet<Id>or aMapkeyed by context to precisely track processed records without interfering with separate batches or operations. - Leverage Trigger Best Practices: Follow patterns like one-trigger-per-object and use trigger handler classes. Not only does this organize your code, but it also provides a central place to manage recursion control. Many seasoned developers use trigger frameworks that inherently handle recursion and order of execution concerns. If you’re not using a formal framework, you can still apply the principles manually in your handler logic.
- Mind the Governors: Always consider how recursion (intentional or not) impacts governor limits. Check that your recursive code won’t perform unbounded SOQL/DML calls. If you must do recursion with queries (like traversing a hierarchy), try to structure it to stay within limits (e.g., limit depth, or retrieve data in chunks). Monitor CPU time for heavy recursion, what works for 10 levels might not work for 500 levels.
- Recursion vs. Performance: Recursion often makes code easier to read and write for hierarchical problems, but it may run slower than an iterative solution in Apex. Use it judiciously and test the performance. If an iterative approach or a bulk SOQL can achieve the same result more efficiently, consider that for large-scale operations.
- Engage Controlled Recursion Where Appropriate: Don’t be afraid of recursion when it provides a clear solution, just implement it in a controlled manner. Whether it’s traversing an Account hierarchy to build a tree, or breaking down a complex job into simpler recursive steps, recursion can be a clean approach. Just always include those safety checks and document the expected behavior.
By understanding and applying these practices, you can avoid the common recursion pitfalls (like infinite trigger loops) and confidently use recursion as a tool in your Apex development toolbox. Remember, in Salesforce, automation can be interconnected, one change can trigger a cascade. Being aware of recursion is part of writing robust, professional-grade Apex code. Happy coding, and may your triggers never go wild!